大纲
- IndexedDB 介绍
- IndexedDB vs Web SQL
- IndexDB 的核心对象
- IndexedDB 的 CRUD
- IndexedDB 实践
IndexedDB 介绍
- 由浏览器支持底层 API,用来存储大量数据
- 对 DB 的所有操作都是异步的
- 基于事务
- 支持索引
- Key->Value 存储,支持所有类型数据
indexedDB VS Web SQL
对比
| indexedDB | Web SQL | |
|---|---|---|
| 兼容性 | 高 | 低(规范已经废弃,大部分浏览器不再支持) |
| 入门门槛 | 低 | 高,需要额外学习 SQL |
| 性能 | 高 | 低 |
由于 Web SQL 的规范已经废弃,官方说法是因为无法走标准化的流程,大概意思是你都用 SQL 了,本身就是一个标准化的东西,每个浏览器实现几乎一样,没有多样性了,没法进行标准的演进,所以废弃了。
具体可以看官方的说明:
https://dev.w3.org/html5/webdatabase/
写法对比


从上面的写法可以看出,indexedDB 更适合前端开发,因为不涉及任何的 SQL 语句,而 web SQL 所有的操作基本都是使用 SQL 来完成的。
IndexedDB 核心对象介绍
- IDBDatabase: 数据库对象
- IDBObjectStore:对象仓库
- IDBRequest:操作请求
- IDBIndex:索引
- IDBTransaction:事务
- IDBCursor:游标
- IDBKeyRange:索引范围
IDBDatabase 表示数据库对象,在操作 indexedDB 之前,我们必须指定数据库。
IDBObjectStore 表示对象仓库,类似关系型数据库的表。
IDBRequest: 操作请求对象,indexedDB 每个操作都是异步的,也就是说每个请求会先返回这个这个对象,然后根据这个对象的回调去进行后续的处理。
IDBIndex: 索引,索引主要用来加快数据查询的效率,但同时会增加存储的占用,本质上是一种空间换时间的方式。
IDBTransaction: indexedDB 的所有操作都是基于事务的,事务具有 ACID 四大特性。
IDBCursor: 游标对象,主要用来遍历数据。
IDBKeyRange: 索引范围对象,主要用来批量查询数据,或者批量删除数据的时候使用。
IndexedDB 基本操作
创建数据库

调用 indexedDB.open 接口来打开或者创建数据库。
- 数据库名称: 必填参数
- 数据库版本: 可选参数
这个接口第一个参数是数据库名称,第二个参数是数据库版本,如果传入的数据库版本比当前的数据库版本高,就会触发数据库版本升级事件。
创建 IDBObjectStore

因为 indexedDB 多有的操作都是基于事务的,所以在创建 ObjectStore 之前,需要先创建一个事务,就是这里的 db.transaction, 第一个参数是事务的名称,第二个参数是事务的 mode,主要有这几种。
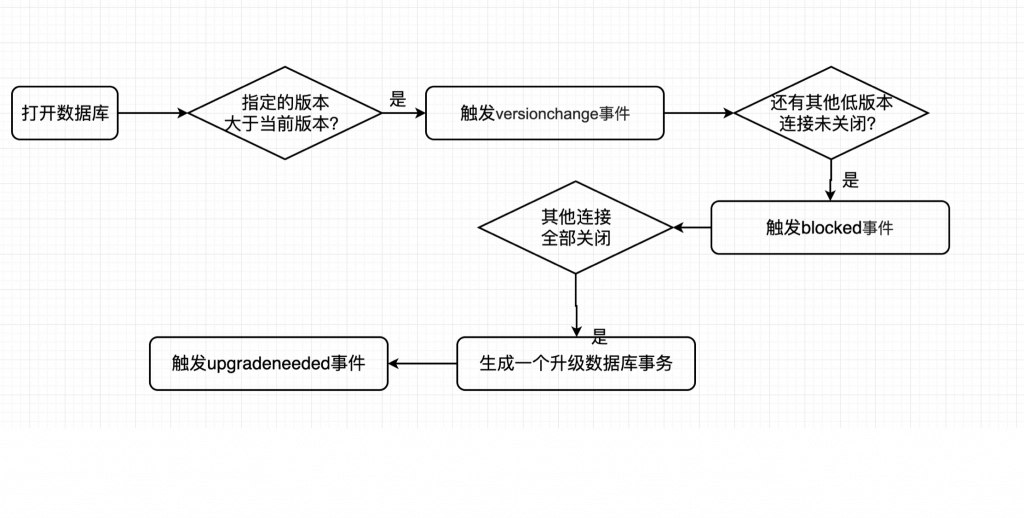
其中,versionchange 事件由 indexedDB 自动创建,在 upgradeneeded 事件触发的时候自动创建。
创建 ObjectStore 的时候,可以指定参数,这里主要有两个可选的参数,一个是 keyPath,这个表示你要使用 value 当中的哪个属性来作为主键,可以是子属性。如果没有合适的属性用来作为主键,可以指定 autoIncrement 属性为 true,这样 indexed 就会自动帮你生成自增主键。不需要你自己维护。那如果两个都不传呢?新增的时候由外部通过 add 方法的第二个参数传入,否则就会报错。如果两个都设置的话,keyPath 生效。
新增数据

修改数据
根据自增主键更新:

根据 keyPath 更新:

删除数据
根据主键删除:

因为我们指定了 isbn 为 keyPath,所以这里我们更新的时候就会更加 isbn 去更新数据。
根据 KeyRange 删除:
|
1 |
var request = objectStore.delete(KeyRange); |
注意这里的 KeyRange 是指主键的 KeyRange。
查询
根据主键查询

索引介绍

通过 ObjectStore 对象的 createIndex 索引可以根据指定的属性来创建索引,上图中根据 title 属性来创建一个唯一索引。
如果不指定 unique:true,则表示创建普通的索引。
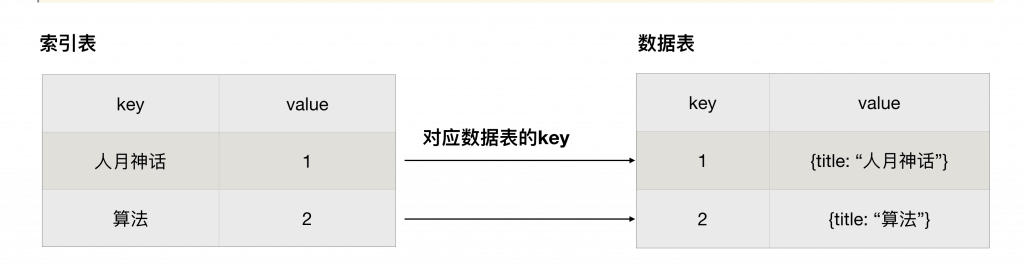
索引表的结构类似上图,通过将索引和数据表的 key 关联起来,这样查询的时候,先通过索引找到所有的对应的记录的 key,然后根据 key 去数据表查询,加快查询速度。
根据索引查询
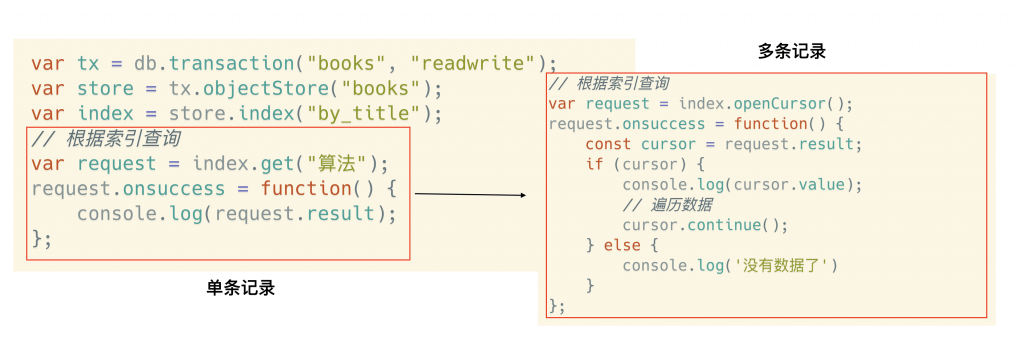
索引高级用法:IDBKeyRange

通过 IDBKeyRange 对象,可以用来根据索引查询符合要求的各种数据。上面的列子表示用索引来查询 title='人月神话'的记录数据。
indexedDB 事件介绍
-
success:请求成功
-
error:请求失败
-
abort:事务终止事件(提交事务失败时触发)
-
close:数据库连接关闭(数据库不正常关闭时触发)
-
upgradeneeded:数据库升级成功
-
blocked:请求被阻塞的事件(存在低版本连接时触发)
-
versionchange: 版本变更事件
打开数据库流程:
插入数据流程:
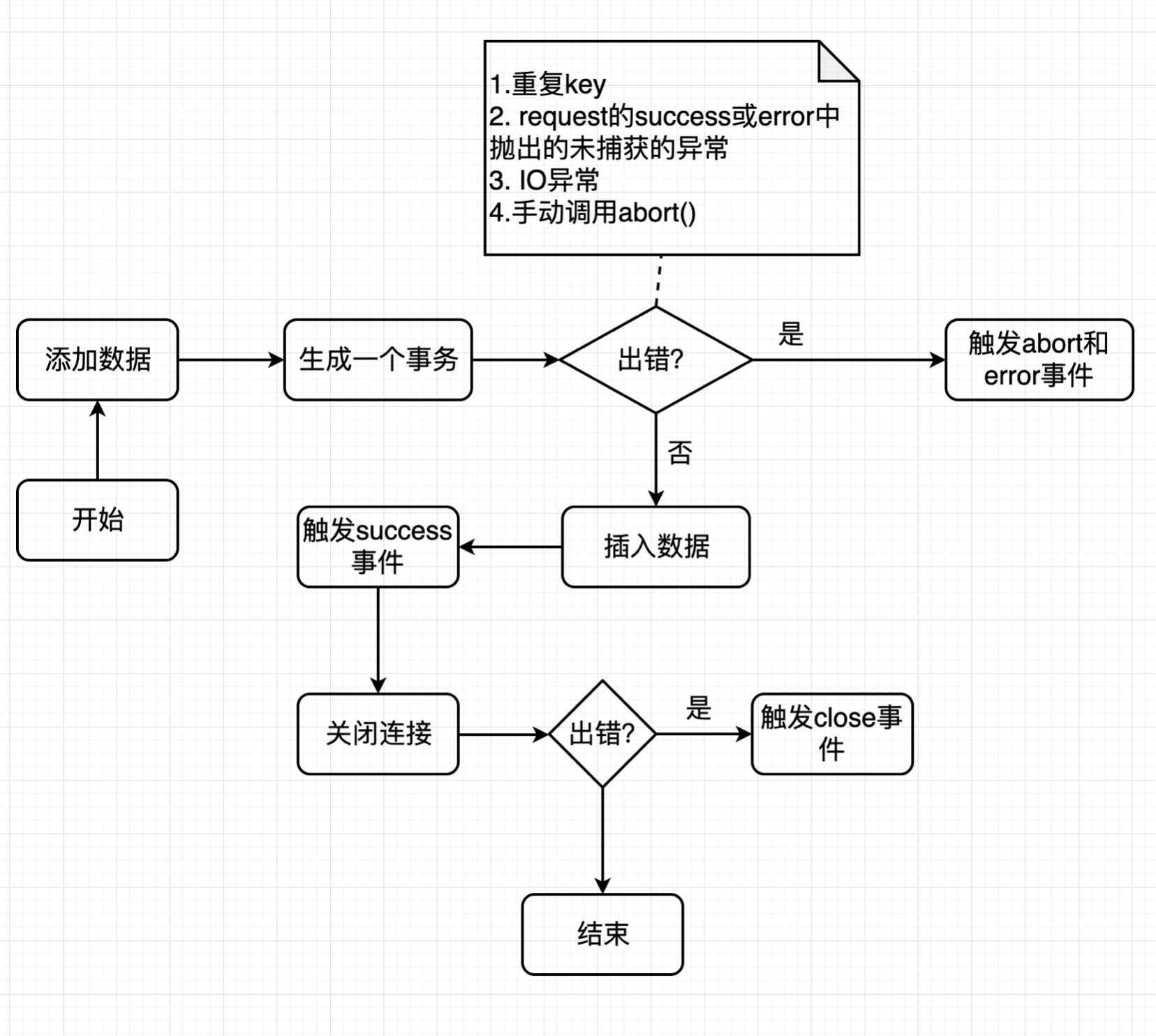
通过上面的两个流程图,基本上涉及了 indexedDB 中的所有事件。
一个实际例子
在项目中需要如果需要使用 IndexedDB 来存储离线日志,日志记录的主要字段有时间戳(ts)和日志内容(msg)。考虑以下场景:
- 根据时间戳范围查询日志
- 根据时间戳范围删除日志
如果我们直接根据时间戳查询,我们需要遍历整个表的数据,依次比较每条记录的 ts 是否在查询的范围内。
既然 indexedDB 可以使用索引,那我们能不能改造下存储的字段结构,利用上 indexedDB 的索引能力呢?
我们来看个图:
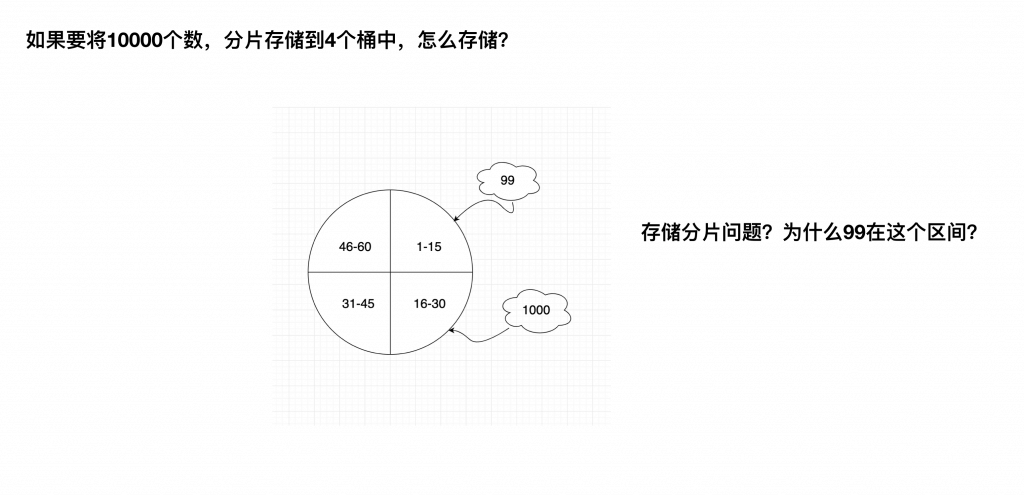
上面的图表示将 1 小时分成 4 份,然后用来存储数据。那为什么 99 是在第一个区域,而 1000 是在第二个区域呢。
其实非常简单,就是通过取模来实现的,99 / 60 = 1, 1000 / 60 = 16。
这样我们就可以将连续的数据放到 4 个区间里面去。那再来看下上面的问题,我们是否可以讲时间戳也这样处理呢?
肯定是可以的,我们来看下使用索引之后的实现,添加一个 timeFragment 字段作为索引:
首先需要根据取模后的时间戳值来创建索引
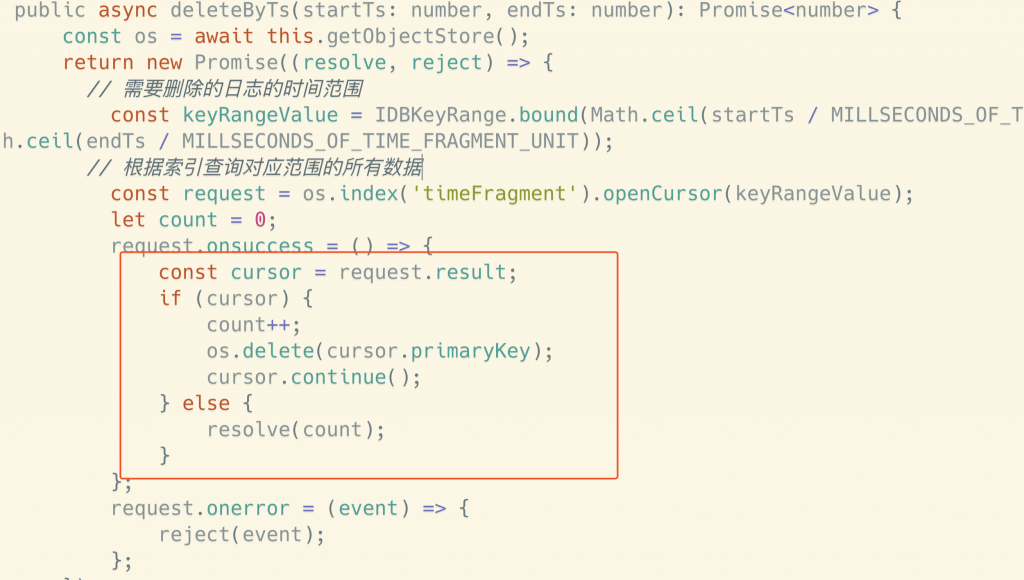
在报错数据的时候,我们可以通过以下方法来存储数据:

下面是根据时间戳来删除数据:
目前的存储结构:
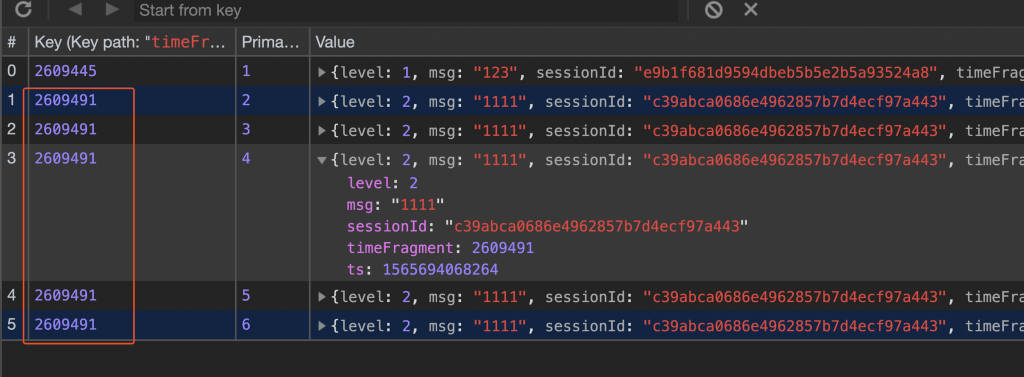
通过上面的改造,就可以很好的支持时间戳的范围查询了。
