正则表达式可能大部分人都用过,但是大家在使用的时候,有没有想过正则表达式背后的原理,又或者当我告诉你正则表达式可能存在性能问题导致线上挂掉,你会不会觉得特别吃惊?
我们先来看看 7 月初,因为一个正则表达式,导致线上事故的例子。
https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
简单来说就是一个有性能问题的正则表达式,引起了灾难性回溯,导致 cpu 满载。
性能问题的正则
先看看出问题的正则

引起性能问题的关键部分是 .*(?:.*=.*) ,这里我们先不管那个非捕获组,将性能问题的正则看做 .*.*=.* 。
其中 . 表示匹配除了换行以外的任意字符(很多人把这里搞错,容易出 bug), .* 表示贪婪匹配任意字符任意次。
什么是回溯
在使用贪婪匹配或者惰性匹配或者或匹配进入到匹配路径选择的时候,遇到失败的匹配路径,尝试走另外一个匹配路径的这种行为,称作回溯。

可以理解为走迷宫,一条路走到底,发现无路可走就回到上一个三岔口选择另外的路。
回溯现象
|
1 2 3 4 5 6 7 8 9 |
// 性能问题正则 // 将下面代码粘贴到浏览器控制台运行试试 const regexp = `[A-Z]+\\d+(.*):(.*)+[A-Z]+\\d+`; const str = `A1:B$1,C$1:D$1,E$1:F$1,G$1:H$1` const reg = new RegExp(regexp); start = Date.now(); const res = reg.test(str); end = Date.now(); console.log('常规正则执行耗时:' + (end - start)) |
现在来看看回溯究竟是怎么一回事
假设我们有一段正则 (.*)+\d ,这个时候输入字符串为 abcd ,注意这个时候仅仅输入了一个长度为 4 的字符串,我们来分析一下匹配回溯的过程:
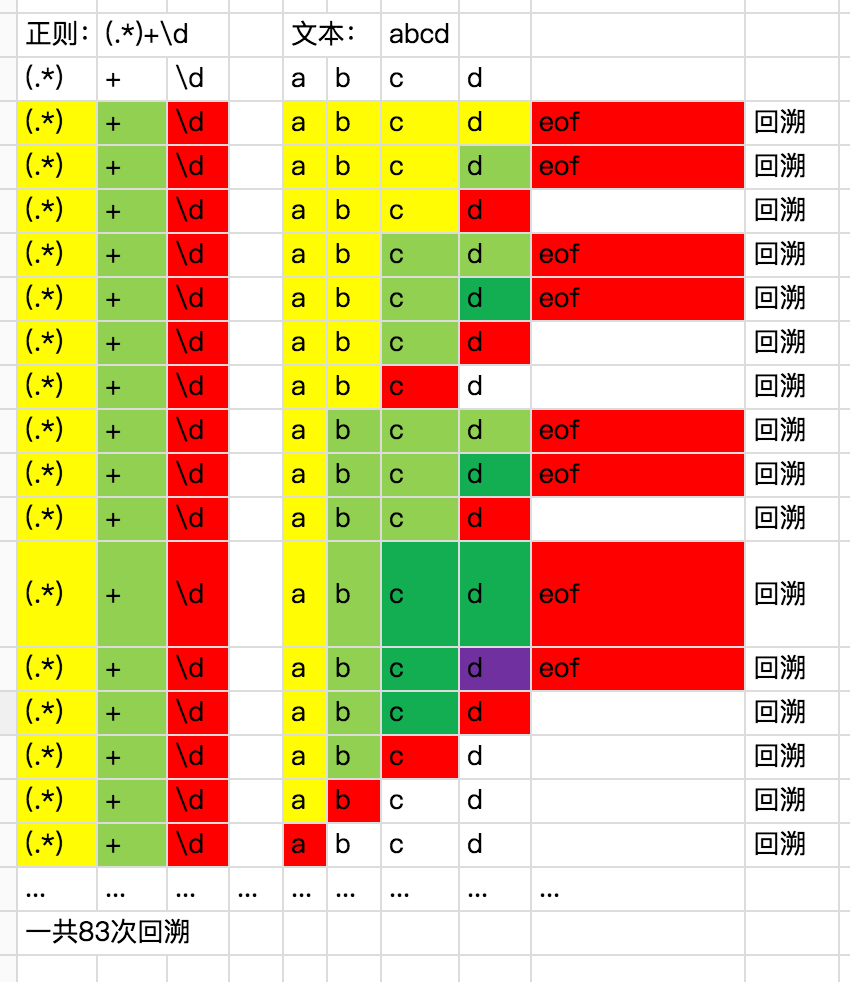
上面展示了一个回溯的匹配过程,大概描述一下前三轮匹配。
注意 (.*)+ 这里可以先暂且看成多次执行 .* 。 (.*){1,}
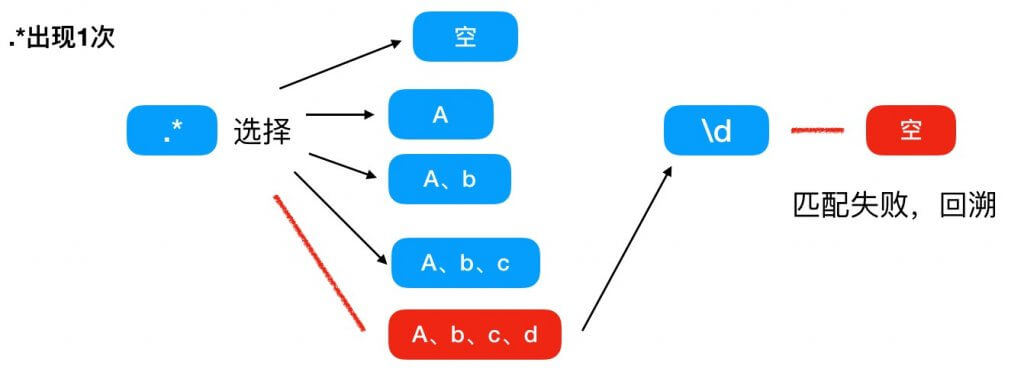
第一次匹配,因为 .* 可以匹配任意个字符任意次,那么这里可以选择匹配空、a、ab、abc、abcd,因为 * 的贪婪特性,所以 .* 直接匹配了 abcd 4 个字符, + 因为后面没有其他字符了,所以只看着 .* 吃掉 abcd 后就不匹配了,这里记录 + 的值为 1,然后 \d 没有东西能够匹配,所以匹配失败,进行第一次回溯。

第二次匹配,因为进行了回溯,所以回到上一个匹配路径选择的时候,上次 .* 匹配的是 abcd ,并且路不通,那么这次只能尝试匹配 abc ,这个时候末尾还有一个 d ,那么可以理解为 .* 第一次匹配了 abc ,然后因为 (.*)+ 的原因, .* 可以进行第二次匹配,这里 .* 可以匹配 d ,这里记录 + 的值为 2,然后 \d 没有东西能够匹配,所以匹配失败,进行第二次回溯。
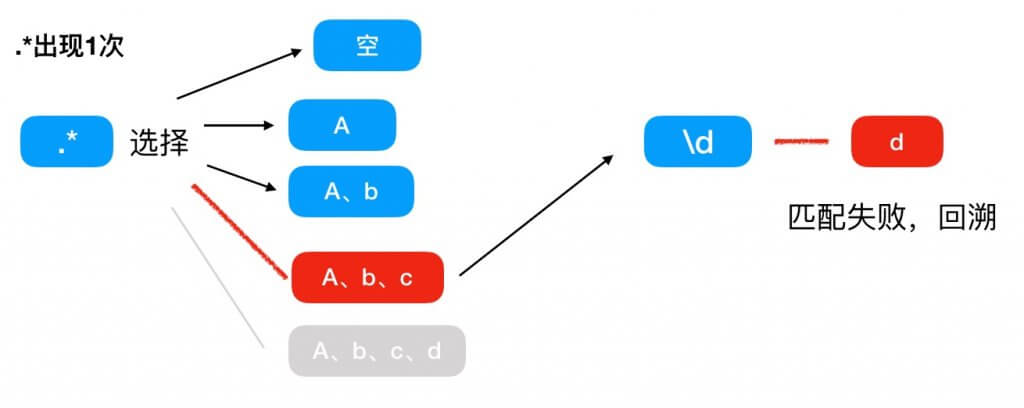
第三次匹配,因为进行了回溯,所以回到上一个匹配路径选择的时候,上次第一个 .* 匹配的是 abc ,第二个 .* 匹配的是 d ,并且路不通,所以这里第二次的 .* 不进行匹配,这个时候末尾还有一个 d , \d 和 d 匹配失败,进行第三次回溯。
如何减少或避免回溯
- 优化正则表达式:时刻注意回溯造成的性能影响。
- 使用 DFA 正则引擎的正则表达式
什么是 DFA 正则引擎
传统正则引擎分为 NFA(非确定性有限状态自动机),和 DFA(确定性有限状态自动机)。
DFA
对于给定的任意一个状态和输入字符,DFA 只会转移到一个确定的状态。并且 DFA 不允许出现没有输入字符的状态转移。
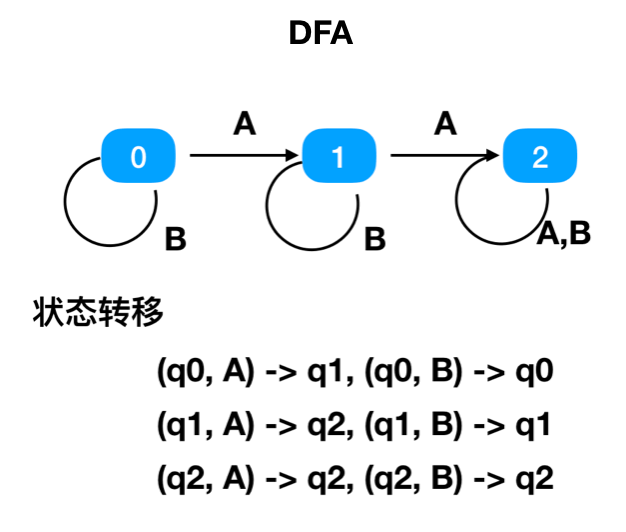
比如状态 0,在输入字符 A 的时候,终点只有 1 个,只能到状态 1。
NFA
对于任意一个状态和输入字符,NFA 所能转移的状态是一个非空集合。
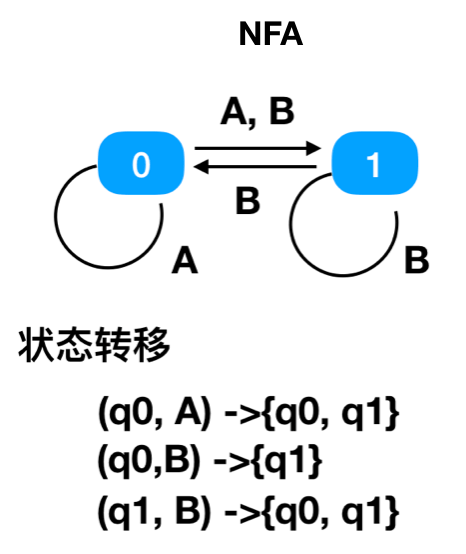
比如状态 0,在输入字符 A 的时候,终点可以是多个,即能到状态 1,也能到状态 0。
DFA 和 NFA 的正则引擎的区别
那么讲了这么多之后,DFA 和 NFA 正则引擎究竟有什么区别呢?或者说 DFA 和 NFA 是如何实现正则引擎的呢?
DFA
正则里面的 DFA 引擎实际上就是把正则表达式转换成一个图的邻接表,然后通过跳表的形式判断一个字符串是否匹配该正则。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// 大概模拟一下 function machine(input) { if (typeof input !== 'string') { console.log('输入有误'); return; } // 比如正则:/abc/ 转换成DFA之后 // 这里我们定义了4种状态,分别是0,1,2,3,初始状态为0 const reg = { 0: { a: 1, }, 1: { b: 3, }, 2: { isEnd: true, }, 3: { c: 2, }, }; let status = 0; for (let i = 0; i < input.length; i++) { const inputChar = input[i]; status = reg[status][inputChar]; if (typeof status === 'undefined') { console.log('匹配失败'); return false; } } const end = reg[status]; if (end && end.isEnd === true) { console.log('匹配成功'); return true; } else { console.log('匹配失败'); return false; } } const input = 'abc'; machine(input); |
优点:不管正则表达式写的再烂,匹配速度都很快
缺点:高级功能比如捕获组和断言都不支持
NFA
正则里面 NFA 引擎实际上就是在语法解析的时候,构造出的一个有向图。然后通过深搜的方式,去一条路径一条路径的递归尝试。

优点:功能强大,可以拿到匹配的上下文信息,支持各种断言捕获组环视之类的功能
缺点:对开发正则功底要求较高,需要注意回溯造成的性能问题
总结
现在回到问题的开头,我们再来看看为什么他的正则会有性能问题
- 首先他的正则使用的 NFA 的正则引擎(大部分语言的正则引擎都是 NFA 的,js 也是,所以要注意性能问题产生的影响)
- 他写出了有性能问题的正则表达式,容易造成灾难性回溯。
如果要避免此类的问题,要么提高开发对正则的性能问题的意识,要么改用 DFA 的正则引擎(速度快,功能弱,没有捕获组断言等功能)。
注意事项
在平常写正则的时候,少写模糊匹配,越精确越好,模糊匹配、贪婪匹配、惰性匹配都会带来回溯问题,选一个影响尽可能小的方式就好。写正则的时候有一个性能问题的概念在脑子里就行。
tips:之前我用 js 写了一个 dfa 的正则引擎,感兴趣的同学可以看看:https://github.com/libertyzhao/mini-regexp
